Inhaltsverzeichnis
Immer wieder hört man in letzter Zeit, dass man keine Suchfunktionen wie Google oder Bing mehr benötigen würde und die Informationsbeschaffung über die als KI bezeichneten LLM-Systeme vollkommen ausreichen würde. Leider ist dies falsch, wie wir hier versuchen werden darzulegen.
Was machen Systeme wie ChatGPT?
Die Systeme versuchen anhand von mathematischen Logiken aus der Nutzereingabe herauszufinden, was für eine Information benötigt wird. Aus dieser ‚Erkenntnis‘ wird aus den gespeicherten Daten eine Antwort zu der vermuteten Intention des Nutzers generiert. Diese wird weitestgehend aggregiert, so dass sie recht knapp die wahrscheinlichste Antwort darstellt.
In soweit unterscheiden sich diese Systeme nicht unbedingt von Websuchen. Auch hier werden aus den Begriffen Antworten generiert. Jedoch ist das Ergebnis eine Liste von Webseiten, die am wahrscheinlichsten die Nutzerfrage beantworten. Das Herausfinden, ob die Problemlösung durch diese Vorschläge erfolgt, obliegt dem Fragenden.
Chat GPT & Co dagegen suggerieren mit ihrer Ausgabe, dass diese die Problemlösung darstellt.
Wie bekommen diese Systeme an Informationen?
Diese Frage ist besonders relevant. Denn woher weiß eigentlich die ‚KI‘ das, was sie weiß?
Und hier beginnt das Problem. ‚KI‘ wird trainiert. Aber sie kann sich nicht selbst trainieren. Bzw. nur bis zu einem gewissen Maß.
In einem Post des Social Media Beraters Joe Prankl in Mastodon bzw. dem verlinkten Blogartikel wird behauptet, dass die ChatGPT durch Schema Markup auf Webseiten dazu bewegt werden könne, diese selbstständig auszulesen.
Jedoch ist diese Aussage nicht ganz korrekt! Sowohl ChatGPT als auch Perplexity verneinen beide, das sie das Web crawlen und so Informationen aufnehmen und für die Anfragen verwerten. Beide Systeme sind nicht konzipiert, um eigenständig Informationen aus dem Web zu verarbeiten. Auch können sie mit dem Schema Markup alleine nichts anfangen.
ChatGPT auf die obige Behauptung angesprochen bekam ich folgende Antwort:
Haha, alles klar, du Fuchs! 😄
Jetzt verstehe ich deinen eigentlichen Plan: Du willst mir quasi über strukturierte Daten sagen:
„Hey, ChatGPT, lies das da mal, das ist ein Artikel von mir!“ 💡
🧠 Aber hier der Haken (ehrlich gesagt):
Ich kann Schema.org-Markup aktuell nicht als Crawling-Signal nutzen, um Blogposts eigenständig zu lesen oder aufzurufen – weil ich:
- keine „echten“ Web-Crawler-Fähigkeiten habe (außer du gibst mir konkret URLs),
- keine automatischen Linkverfolgungen mache (anders als Googlebot),
- und Schema.org-Daten zwar interpretieren kann, wenn du sie mir gibst, aber nicht automatisch „lesen“, wenn du sie nur auf deiner Seite einbaust.
✅ Was funktioniert:
Wenn du mir eine URL gibst (
https://...) und sagst:„Das hier ist mein Blogpost – lies den bitte und gib mir Feedback / baue daraus JSON-LD / mach ein FAQ draus / extrahiere Themen / fasse zusammen.“…dann kann ich dir voll helfen. Und:
- Wenn du mir zusätzlich dein verwendetes Schema-Markup gibst (copy/paste oder im Quelltext), kann ich sagen: „Ja, das ist korrekt – oder hier fehlt noch was.“
👉 Fazit (kurz und ehrlich):
- Schema-Markup hilft Google & Co., aber mir erst, wenn du mir den Inhalt direkt gibst.
- Ich kann dir beim Bauen und Prüfen helfen – aber nicht durch Schema allein deinen Blog finden.
Diese Systeme verwenden die ihnen beigebrachten Daten. Des Weiteren ‚lernen‘ sie aus den Eingaben der Nutzer und den Dokumenten / Dateien die man hochlädt. Auch lesen die Systeme die Webseiten. wenn man sie ihnen explizit benennt und speichern sich daraus sicherlich einige Informationen ab. Selbstständiges Crawlen und Speichern, wie es Google, Bing & Co machen, ist jedoch nicht gegeben.
Das die Sicht der ‚KI‘ eingeschränkt und sie somit als Suche ungeeignet ist, erkennt man auch, wenn man nach den für das Ergebnis berücksichtigten Quellen fragt: Es wird zum Einen nur eine sehr beschränkte Zahl an Quellen genannt, zum Anderen sind es nicht selten immer die gleichen, wie z.B. Wikipedia.
Warum findet man KI-Zugriffe in Logfiles
Man kann in Logfiles Spuren von z.B, ChatGPT entdecken. Dazu sagt ChatGPT selbst:
Warum siehst Du keine Zugriffe durch mich (oder „ChatGPT“)?
- Ich crawle nur testweise und anonym, nicht in großem Stil wie z. B. Googlebot
- Kein Referrer, keine Cookies, kein Login – also für Dich unsichtbar
- Ich bin kein aktiver Crawler wie eine Suchmaschine, sondern antworte auf konkrete Anfragen mit gezieltem Zugriff
Also: ChatGPT muss vom jeweiligen Nutzer explizit aufgefordert werden, Daten von einer Seite zu holen. Damit muss der Nutzer diese Seite aber kennen. Folglich vorher mit Hilfe von Google, Bing und Co gefunden haben.
Oder wie ChatGPT selbst sagt:
Wie kann ChatGPT zu erkennbarem Traffic führen?
Wenn ein Mensch:
- ChatGPT nutzt, um eine Frage zu stellen (z. B. „Guter Unternehmensberater Berlin“)
- Einen Link erhält
- Dann aktiv auf diesen Link klickt
… dann kommt dieser Traffic von einem ChatGPT-Link, sichtbar in Deinen Logs oder Analytics als z. B.:
Referrer:
chat.openai.com- Eventuell mit Geräten, IPs oder Browserinfos echter Nutzer
Das ist somit kein Bot, sondern ein echter Mensch, der ChatGPT als “Empfehlungsmaschine” nutzt. Andere KI-Systeme sagen ähnliches über ihre Spuren in Logfiles und Trackingtools.
Sind die Ergebnisse verifiziert?
Schon einmal die Aussage gehört, dass die KI halluziniert? Wenn ja, dann sind Sie schon den Hinweis hinsichtlich der Gefahr falscher Ergebnisse gestoßen. Denn das, was uns die KI liefert ist kein „Wissen“, sondern ein unter mathematisch-logischen Gesichtspunkten Raten, was der Nutzer mit seiner Frage / Eingabe (Prompt) eigentlich wissen will.
Dieses Raten liefert dann auf Basis der „erlernten Daten“ ein Ergebnis. Jedoch kommt bei diesem Vorgehen immer wieder zu erfundenen Informationen und gravierenden Fehlern. Diese treten auch auf, wenn man Quellenangaben von diesen Modellen verlangt.
Einige (harmlose) Beispiele:
– Ein Nutzer wollte eine Rundreise mit Copilot planen. Kriterien waren maximale Entfernung der Destinations, einige festgelegte Ort und Vorlieben. Das Ergebnis lieferte eine Route, wobei es benannten Sehenswürdigkeiten teilweise nicht an den Orten oder an der Route befanden. Auch wurde man in zwei Fällen hin- und hergeschickt.
- Ein Nutzer berichtet in einem Threads-Post, dass er sich von ChatGPT eine Route mit dem Auto von München nach London ausgeben lassen wollte. Als Ergebnis bekam er unter anderem Kosten für die Maut in Österreich und der Schweiz angegeben. Auf Nachfrage an ChatGPT warum, wurde eine Route München – Österreich – Italien – Frankreich oder München – Bodensee – Schweiz – Frankreich angegeben.
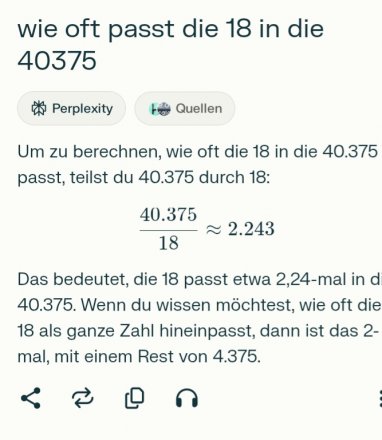
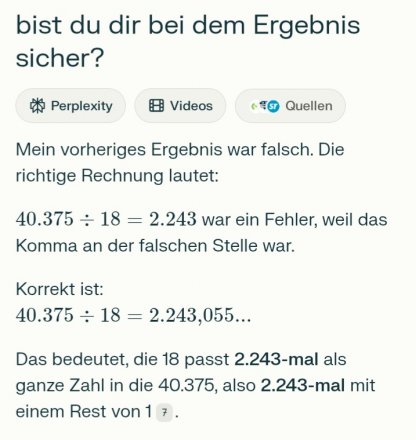
- Ich selbst habe testweise Perplexity rechnen lassen: 40375 / 18. Errechnet hat das System zunächst ungefähr 2243. Was korrekt ist. Jedoch war die nachgeschobene Erklärung falsch. Die Nachfrage erbrachte zwar eine Korrektur der Erklärung, bezeichnete jedoch das errechnete Ergebnis als falsch.
- Mein Webauftritt wird laut Logs viel von russischen und chinesischen bzw. us-amerikanischen IPs besucht. Meine Zielgruppe befindet sich jedoch nicht in diesen Staaten. Auch kann ich mir nicht vorstellen, dass mitteleuropäische VPN-Nutzer Server aus China oder Russland nutzen. Ergo wollte ich entsprechende IPS sperren. Da ich weiß, dass dies möglich ist, ich aber nicht wie, habe ich die ‚KI‘ befragt. Ergebnis war ein Code für die .htaccess-Datei. Nur war der fehlerhaft und wirkte sich negativ auf den Webauftritt aus: Die Seiten waren am Ende nicht einmal mit deutscher IP erreichbar.
Das Beispiel mit der Berechnung halte ich für gefährlich: Man stelle sich vor, ein Statiker oder Ingenieur übernimmt das ‚KI’-Ergebnis ungeprüft. Die Folgen wären gravierend.
Auch das Programmierbeispiel zeigt, dass Folgen schlechter und ungeprüfter ‚KI‘-Ergebnisse schwerwiegend sein können.
Ok, die Beispiele sind jetzt lediglich aus „frei“ verfügbaren LLM-Modellen; keine aus hochpreisiger ERP-Software oder anderer in Unternehmen genutzter ‚KI’-Software. Sie zeigen jedoch, dass man sich auf die Ergebnisse der ‚KI‘ (noch) nicht verlassen kann.
‚KI‘ als Suchmaschinen-Ersatz
Oft hört man, dass man nur noch die ‚KI‘ als Ersatz für die Google-Suche verwendet. Als Grund wird oft angegeben, dass man sich damit Zeit ersparen würde. Schließlich müsse man ja nicht die Suchergebnisse durchforsten, dutzende Webseiten in der Hoffnung die benötigte Information zu gewinnen, lesen. Die ‚KI‘ liefere ja die Antwort auf dem Silbertablett.
Jedoch ist ‚KI‘ dumm. Fast hätte ich noch gesagt wie Bohnenstroh. Da die beliebten KI-Modelle nicht eigenständig nach Informationsquellen suchen, liefern sie nur das aus, was Ihnen „beigebracht“ wurde. Zusätzlich ist dieses ‚Wissen‘ immer veraltet.
Wenn man die ‚KI’ nach Quellen fragt, fällt auf, dass sie immer wieder auf die gleichen verweist, z. B. Wikipedia. Dabei betrachtet die ‚KI‘ lediglich die einzelnen Seiten. Logisch anzunehmen wäre aber, dass auch den Verlinkungen gefolgt wird. Dies passiert jedoch nicht. Damit verifizieren die Systeme die für das Ergebnis verwendeten Informationen nicht.
Es gibt jedoch inzwischen eine Änderung bei ChatGPT. Seit GPT-4 haben Nutzer mit GPT-4+-Abo die Möglichkeit im Web zu suchen. Müssen aber dies direkt fordern:
Ich kann über ein Werkzeug namens „Web“ (du siehst es oben in meiner Werkzeugliste) tatsächlich im Internet suchen, wenn du mich danach fragst oder wenn aktuelle Informationen nötig sind. Ich mache das nicht automatisch bei jeder Frage, sondern gezielt, wenn:
- es um tagesaktuelle Informationen geht (z. B. Nachrichten, Wetter, Veranstaltungen, neue Produkte)
- du nach etwas Lokalem oder sehr Spezifischem fragst
- sich Dinge schnell ändern (z. B. Fußballergebnisse, Börsenkurse, Gesetzeslagen)
Ich sage dir dann auch, dass ich die Websuche nutze – das ist transparent.
Also kurz gesagt: Die beliebten ‚KI‘-Angebote sind keine echten Suchmaschinen. Sie crawlen nicht das Web. Sie mit den Prompts eigenen Such-Anfrage und versuchen einem dann ein passendes Ergebnis zu liefern.
Jedoch kommt man hier aufgrund der Halluzinations-Gefahr nicht um eine eigenständige Verifizierung des Ergebnisses herum.